
Hello,大家好,在我们使用了clickhouse进行数据存储后,多多少少遇到一些棘手的问题,在此记录。
我们使用clickhouse改造后,系统流畅度得到大幅提升,大家有兴趣可以来体验一下效果,Webfunny前端监控和埋点系统
如大家所知,Clickhouse数据有几大优点,很适合处理海量的数据,如:查询效率高、clickhouse号称10亿数据,毫秒级查询返回结果;数据压缩率高、它采用了列式存储,对数据压缩有天然优势,节省硬盘资源;集群化、clickhouse天生支持集群化,同时有分区和分片设计,已经涵盖了我们按天分表的设计;
因此我们义无反顾的采用clickhouse进行了改造,效果确实符合我们要求,但是迎来了第一个问题,硬盘爆了。
咦?不是说存储压缩率高,节省硬盘吗?这还没弄几下,硬盘就爆满了,咋整?今天我们就分三步来告诉大家怎么排查和优化设置。
第一步、对比查找硬盘消耗最多的东西是什么
进入linux服务器,查看总体消耗
硬盘消耗情况查看:df -h
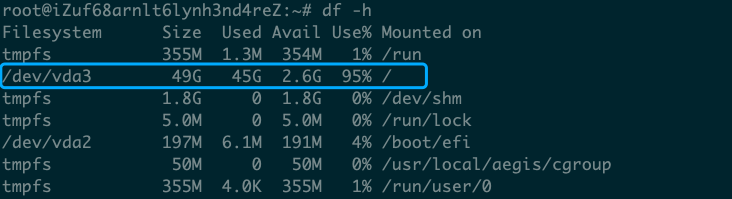
在 Linux 系统中,/dev/vda3 通常是一个设备文件,代表一个磁盘分区,是无法通过cd命令进入的。
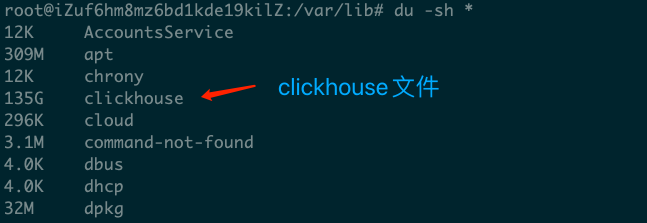
所以我们可以进入 cd / 然后执行 du -sh * 命令来查看硬盘占用细节。
经过一番排查,最终确定是clickhouse对硬盘的消耗最大。
第二步、排查数据库内部占用情况
通过对Table size进行排序,可以看出,数据的总量也不过就是在百兆以内,所以肯定不是业务表消耗的。

既然不是业务表,那么就应该是是系统表消耗的,所以我们在clickhouse官网上找到了关于系统表的描述,原文查看

官网描述中,介绍了有哪些系统表,已经他们的创建规则,所以我们对这些系统表进行注意排查,也许是我的数据库版本原因,有些日志表是找不到的
sql整理如下:
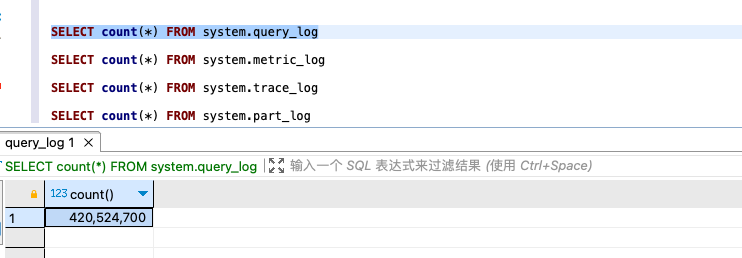
SELECT count(*) FROM system.query_log
SELECT count(*) FROM system.metric_log
SELECT count(*) FROM system.trace_log
SELECT count(*) FROM system.part_log
select count(*) from system.processors_profile_log
select count(*) from system.processors_profile_log_0
select count(*) from system.opentelemetry_span_log
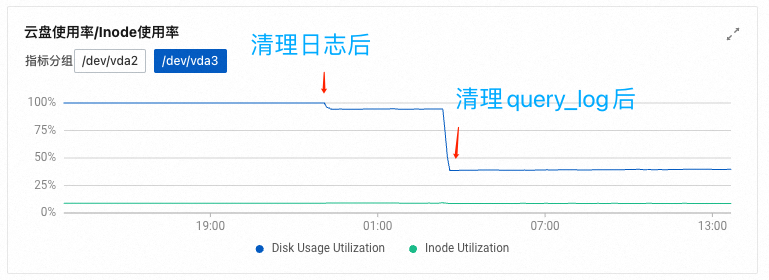
经排查,占用最多的是query_log这个系统表,虽然业务数据才几百兆,但是query_log却有几亿条,是大头,其他log也有百万到千万不等。
接着我们对query_log进行了清理,这一步耗时比较长,要耐心等一会,执行sql如下:
ALTER TABLE system.query_log DELETE
WHERE query_start_time < '2024-10-26 00:00:00'我们先清理的linux系统里的日志文件,然后执行删除sql,可以看到硬盘的消耗明显下降了,由此可以确定硬盘爆满的原因了。
第三步、优化配置和解决方法
clickhouse默认会采集所有的日志备用,但是很多时候我们不会去查看日志,对于不需要的经常去查看这些日志的同学,可以调整配置内容
clickhouse提供了官网配置文档,进入/etc/clickhouse-server/config.xml文件中可以调整各项参数
database: database the system log table belongs to. This option is deprecated now. All system log tables are under databasesystem.table: table to insert data.partition_by: specify PARTITION BY expression.ttl: specify table TTL expression. 这里是设置删除周期,它默认是30天,你可以设置为1天或者其他时间。flush_interval_milliseconds: interval of flushing data to disk.engine: provide full engine expression (starting withENGINE =) with parameters. This option conflicts withpartition_byandttl. If set together, the server will raise an exception and exit.max_size_rows: 分区最大行数,个人认为,如果有必要可以设置小一点
<clickhouse>
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<ttl>event_date + INTERVAL 30 DAY DELETE</ttl>
<!--
<engine>ENGINE = MergeTree PARTITION BY toYYYYMM(event_date) ORDER BY (event_date, event_time) SETTINGS index_granularity = 1024</engine>
-->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<max_size_rows>1048576</max_size_rows>
<reserved_size_rows>8192</reserved_size_rows>
<buffer_size_rows_flush_threshold>524288</buffer_size_rows_flush_threshold>
<flush_on_crash>false</flush_on_crash>
</query_log>
<processors_profile_log>
<database>system</database>
<table>processors_profile_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<max_size_rows>1048576</max_size_rows>
<reserved_size_rows>8192</reserved_size_rows>
<buffer_size_rows_flush_threshold>524288</buffer_size_rows_flush_threshold>
<flush_on_crash>false</flush_on_crash>
<ttl>event_date + INTERVAL 1 DAY DELETE</ttl>
</processors_profile_log>
</clickhouse>第四步、通过sql查看更多硬盘杀手
通过下方sql可以查看更多消耗硬盘的隐形杀手。
SELECT
database,
table,
SUM(rows) AS total_rows,
SUM(data_compressed_bytes) AS compressed_bytes,
SUM(data_uncompressed_bytes) AS uncompressed_bytes,
SUM(primary_key_bytes_in_memory) AS primary_key_memory_bytes
FROM system.parts
WHERE active -- 只查看活跃部分,排除已标记删除的数据
GROUP BY database, table
ORDER BY compressed_bytes DESC
LIMIT 20;
查出来后,如何清理呢?首先,查出这个表的分区名称
SELECT DISTINCT partition
FROM system.parts
WHERE table = 'asynchronous_metric_log';
通过分区名称逐一删除,效率特别高
ALTER TABLE system.asynchronous_metric_log DROP PARTITION '202511';
好了,这个就是我们解决clichouse硬盘爆满的整个过程了,希望对你有帮助。
